周末(7月8日),央视《焦点访谈》节目播出由证监会牵头,联合公安部制作的专题节目《大数据捕“鼠”记》。7月7日,证监会与公安部集中通报了查处利用未公开信息交易违法犯罪,俗称“老鼠仓”的执法情况。
“老鼠仓”是指一些证券公司、基金公司等金融机构从业人员,利用因职务便利知悉的法定内幕信息以外的其他未公开经营信息,如本单位受委托管理资金的交易信息等,违规从事相关交易活动,谋取非法利益或转嫁风险,严重破坏金融秩序、损害投资者利益的行为。用更通俗的话说,就是有基金经理先用自有资金建一个“老鼠仓”,买入某只股票,接着利用基金资金大批量买入,拉高股价,再把“老鼠仓”先买入的股票卖出赚钱。
请点击此处输入图片描述
节目中,在深圳证券交易所的交易监察中心,专业执法人员对着监控室中数据跳跃的显示器密切关注着,市场交易中的数据如果出现“异常”,他们会第一时间看到。
根据节目的介绍,深交所监察中心的“大数据智能监控平台”从2013年正式上线运营。它可以全天处理超过1亿笔的成交记录,还可以在线处理20年以上的数据。另外,上海证监局近期也招了大量大数据研究和挖掘的人才,从事大数据挖掘,专门针对“老鼠仓”。
节目并没有披露这套系统背后的具体原理或者模型,“大数据”、“智能监控”这些词听起来高深,但是要落到实处,必须还是要有模型系统来“预警”的。简单来说,海量的交易数据每天都有,怎么能从数据中发现“猫腻”,这里我们从技术上做一点猜测*:
1、抓“老鼠仓”的本质,其实就是找到哪些交易账户跟基金账户的交易行为高度相关。这里所谓“高度相关”,就是同买同卖,利用基金的建仓来将自己预先埋伏好的仓位拉升赚钱。以前没有“大数据”技术的时候,监管的方法主要是通过监控基金经理等相关从业人员(及亲属)的账号,属于有目的、有针对性的侦察手段。但是随着老鼠仓手段的升级,选择不相关账户进行交易的越来越多,那么原来这种监控手段就有局限性了。在“大数据”技术之下,不需要预设监控账户,所有的A股账户都可以成为被监控的对象,根据交易数据的特征(Pattern)来自动识别。
举个简单例子,近年来比较著名的“老鼠仓”案例是博时基金经理马乐,于2011年3月9日至2013年5月30日担任博时精选股票证券投资基金经理期间,操作自己控制的“金X”、“严XX”、“严XX”三个股票账户,先于、同期或稍晚于其管理的“博时精选”基金账户买入相同股票76只,累计成交金额人民币10.5亿余元,从中非法获利1883.34万元。
在这个案例中,“金X”、“严XX”、“严XX”三个股票账户,与“博时精选”基金账户在某个时间段内的交易数据必定存在很强的相关性。即便这三个股票账户不是马乐及其直系亲属的账户,通过机器学习的模型也一样可以“大海捞针”把他们找到。
2、具体来说,在机器学习中有一类技术叫做“无监督学习”(Unsupervised Learning),就是说数据当中并没有目标答案,而全靠模型本身来进行分析、归类,从而找到特定的规律。这类方法一般用于特征识别(Pattern Recognition)当中。
在上面这个例子中,“无监督学习”方法就可以用来识别潜在的老鼠仓。假如我们以过去3天汇总的交易记录为考察对象,“金X”、“严XX”、“严XX”三个股票账户,与“博时精选”基金账户就会成为数据当中的四个样本点:
| 股票1 | 股票2 | 股票3 | 股票4 | ... | 股票n | |
| “金X” | 0 | 30% | 30% | 40% | ... | 0 |
| “严XX” | 0 | 40% | 30% | 30% | ... | 0 |
| “严XX” | 0 | 35% | 35% | 30% | ... | 0 |
| ... | ... | |||||
| “博时精选”基金账户 | 0 | 30% | 35% | 35% | ... | 0 |
| ... |
上面这个表里面,每一行代表了一个交易账户,每一列代表了一只可交易的证券(股票)。可以看到,这三个“老鼠仓”账号与基金账号在统计期间内,交易的行为极其类似(都购入了2、3、4三只股票),即使他们建仓的比例可能不尽相同,但是这完全不妨碍模型将他们“挖掘”出来。
实际上,一个简单的K-means算法(K-Nearest Neighbors)就可以完成这个任务。这个算法可以在没有任何预设信息的情况下,仅仅根据输入的特征(Features,在这里就是每只股票建仓的比例数据),来找到相似的账户。这里K值代表的是要分组的数量,K值越高,分组越细。
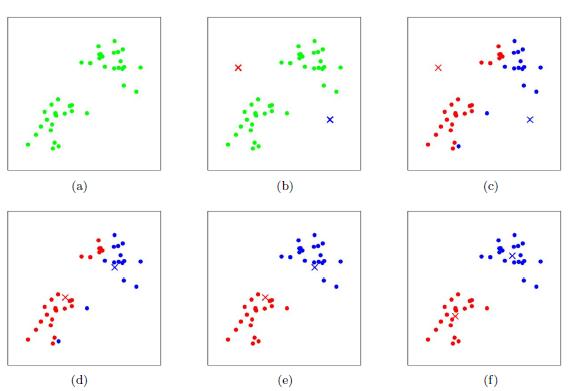
3、K-means等机器学习的算法可以在没有任何预设信息的情况下将可疑的分组给出,然后再结合相关性分析等统计手段具体检验账户之间的关联性。再进一步的,就是立案调查,寻找证据。除了大数据挖掘之外,证监会还增加了对手机、日常通讯工具(包括微信、QQ、私信等社交工具)的监控以及数日内的恢复等高科技手段,确保证据确凿,一击必中。
实际上这些机器学习的技术手段已经存在很长时间了,之所以现在才能够被应用起来,很大程度上是受到了硬件以及人才方面的限制。
在上面的例子中,所有A股账户数量超过2亿(行数),沪深可交易的股票数量3000家左右(列数)。对这么大的一个数据集运行一次模型,如果没有非常强的硬件和系统支持,本身就是不可想象的事情,更何况类似的运算要反复、动态的进行(上面的例子虽然简单,但是有很多的细节在建模的时候都要考虑清楚,比如说统计交易区间的选择,相似性的定义等等,每变换一个参数就意味着重新进行一次运算)。
根据证监会最新发布的《2016年度证监会稽查执法情况通报》显示,2015年“老鼠仓”案件立案查处32起,2016年新增立案案件28起总计达60起,同比增长87%。在大数据技术、机器学习的算法支持下,“老鼠仓”行为的确变得“无可遁形”了。
*上述分析只是我们的猜测,不代表任何监管机构的观点
【注】文章首发于公众号“量化风险研究”,公众号ID:RiskQuant。转载请注明。

0
推荐
 京公网安备 11010502034662号
京公网安备 11010502034662号 {kind=link}